SQL vs. NoSQL
Tables
- Glossary
- Database Models
- SQL vs NoSQL: High Level Differences
- The “Many Faces” of NoSQL
- SQL vs. NoSQL - Which to use?
- Reference
Glossary ⤴
Database Models ⤴
- The Relational Model
- The Model-less (NoSQL) Approach
Database Management Systems (DBMS) ⤴
DBMS are higher-level software, working with lower-level application programming interfaces (APIs), that take care of these operations like: create, retrieve, update and manage data.
To help with solving different kind of problems, for decades new kinds of DBMSs have been developed (e.g. Relational, NoSQL, etc.) along with applications implementing them (e.g. MySQL, PostgreSQL, MongoDB, Redis, etc).
Database Management System is an umbrella term that refers to all sorts of completely different tools (i.e. computer programs or embedded libraries), mostly working in different and very unique ways. These applications handle, or heavily assist in handling, dealing with collections of information.
Since information (or data) itself can come in various shapes and sizes, dozens of DBMS have been developed, along with tons of DB applications, since the second half of the 21st century to help in solving different programming and computerisation needs.
Each database management system implements a different database model (structures defined for handling the data) to logically structure the data that is begin managed.
Popular Database Management Systems:
- Relational Database Management Systems.
- NoSQL (NewSQL, Not only SQL, Model-less) Database Systems.
SQL vs NoSQL: High Level Differences ⤴
| SQL | NoSQL | |
|---|---|---|
| Are primarily called as Relational Databases (RDBMS). | Are primarily called as non-relational or distributed database. | |
| Data storage | Are table based databases. This means that SQL databases represent data in form of tables which consists of n number of rows of data. Rows contain all of the information about one specific entry/entity, and columns are all the separate data points. | The term “NoSQL” encompasses a host of databases, each with different data storage models. The main ones are: document based, key-value pairs, graph databases, wide-column stores. This means NoSQL databases are the collection of key-value pair, documents, graph databases or wide-column stores which do not have standard schema definitions which is needs to adhered to. |
| Schemas and Flexibility | SQL databases have predefined schema. Meaning the columns must be decided and locked before data entry. Each row must contain data for each column. This can be amended, but it involves altering the whole database and going offline. | NoSQL databases have dynamic schema for unstructured data |
| For scalability | Because the way they are structured, SQL databases are vertically scalable by increasing the horse-power of the hardware. In essence, more data means a bigger server –> expensive. It is possible to scale RDBMS across multiple servers, but this is difficult and time-consuming process | NoSQL databases are horizontally scalable by increasing the databases servers in pool of resources to reduce the load |
| Uses SQL (structured query language) for defining and manipulating the data, which is very powerful | Queries are focused on collection of documents. Sometimes it is also called as UnSQL (Unstructured Query Language). The syntax of using UnQL varies from database to database | |
| Are good fit for the complex query intensive environment | Are not good fit for complex queries. On a high-level, NoSQL don’t have standard interfaces to perform complex queries, and the queries themselves in NoSQL are not as powerful as SQL query language | |
| For type of data to be stored | SQL databases are not best fit for hierarchical data storage | Fits better for the hierarchical data storage as it follows the key-value pair way of storing data similar to JSON data. NoSQL databases are highly preferred for large data set (i.e. for big data) |
| For high transactional based application | Are best fit for heavy duty transactional type applications, as it is more stable and promises the atomicity as well as integrity of the data | We can use NoSQL for transactions purpose, it is still not comparable and sable enough in high load and for complex transactional applications |
| For support | Excellent support are available for all SQL database from their vendors. There are also lot of independent consultations who can help you with SQL database for a very large scale deployments | You still have to rely on community support, and only limited outside experts are available for you to setup and deploy your large scale NoSQL deployments |
| For properties | Emphasizes on ACID properties (Atomicity, Consistency, Isolation and Durability) | Follows the Brewers CAP theorem (Consistency, Availability and Partition tolerance) |
| For DB types | On a high-level, we can classify SQL databases as either open-source or close-source from commercial vendors | Can be classified on the basis of way of storing data as graph databases, key-value store databases, document store databases, column store database and XML databases |
The “Many Faces” of NoSQL ⤴
Document Databases ⤴
This image from Document Database solution CouchDB sums up the distinction between RDBMS and Document Databases pretty well:
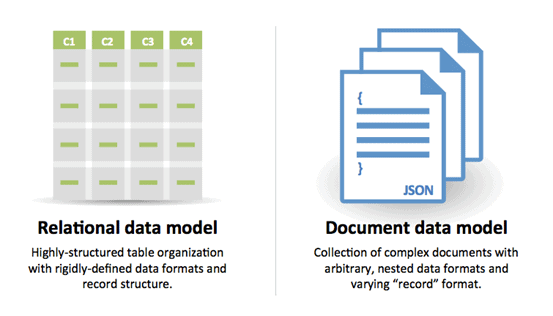
Instead of storing data in rows and columns in a table, data is locked in documents, and these documents are grouped together in collections.
Each document can have a completely different structure.
Some names: CouchDB, MongoDB.
Key-Value Stores ⤴
Data is stored in an associative array of key-value pairs. The key is an attribute name, which is linked to a value.
Some names: Redis, Voldemort (developed by LinkedIn) and Dynamo (developed by Amazon).
Graph Databases ⤴
Used for data whose relations are represented well in a graph. Data is stored in graph structures with notes (entities), properties (information about the entities) and lines (connections between the entities).
Some names: Neo4j, InfiniteGraph.
Columnar (or Wide-Column) Databases ⤴
Instead of ‘tables’, in columnar databases you have column families, which are containers for rows.
Unlike RDBMS, you don’t need to know all the columns up front, each row doesn’t have to have the same number of columns. Columnar databases are best suited to analysing huge datasets.
Some names: Cassandra and Hbase.
SQL vs. NoSQL - Which to use? ⤴
The idea that SQL and NoSQL are in direct opposition and competition with each other is flawed one, because many companies use them concurrently. There is not a one-system-fits-all approach, choosing the righ technology hinges on the use case.
If your data needs are changing rapidly, you need high throughput to handle growth, or your data is growing fast and you need to be able to scale out quickly and efficiently, maybe NoSQL is for you.
But if the data isn’t changing in structure and you’re experiencing moderate, manageable growth, you needs may be best met by SQL technologies.
Leave a Comment